Глава 1. Компромиссы в архитектуре систем обработки данных (доступна)
Не существует готовых решений, есть только компромиссы. […] Но вы стараетесь найти наилучший компромисс, на который способны, и это всё, на что можно рассчитывать.
Томас Соуэлл, Интервью с Фредом Барнсом (2005)
Примечание для читателей раннего выпуска
Благодаря электронным книгам раннего выпуска вы получаете книги в их первоначальном виде — необработанный и неотредактированный контент автора в процессе написания — что позволяет воспользоваться этими технологиями задолго до официального выхода данных изданий.
Это будет 1-я глава финальной книги. Репозиторий GitHub для этой книги находится по адресу https://github.com/ept/ddia2-feedback.
Если вы хотите активно участвовать в рецензировании и комментировании данного черновика, пожалуйста, свяжитесь с нами через GitHub.
Данные являются центральным элементом разработки большинства приложений сегодня. С появлением веб- и мобильных приложений, программного обеспечения как услуги (SaaS) и облачных сервисов стало нормой хранить данные множества пользователей в общей серверной инфраструктуре данных. Данные от пользовательской активности, бизнес-транзакций, устройств и датчиков необходимо сохранять и предоставлять для анализа. Когда пользователи взаимодействуют с приложением, они одновременно читают хранящиеся данные и генерируют новые.
Небольшие объёмы данных, которые можно хранить и обрабатывать на одной машине, обычно довольно просто обслуживать. Однако по мере роста объёма данных или частоты запросов их необходимо распределить между несколькими машинами, что создаёт множество сложностей. Когда требования приложения становятся более комплексными, уже недостаточно хранить всё в одной системе — может потребоваться объединить несколько систем хранения или обработки, предоставляющих различные возможности.
Мы называем приложение системой интенсивной обработки данных (data-intensive), если управление данными является одной из основных сложностей в разработке приложения [1]. В то время как в вычислительно-интенсивных (compute-intensive) системах проблема заключается в распараллеливании очень больших вычислений, в системах интенсивной обработки данных мы обычно больше беспокоимся о таких вещах, как хранение и обработка больших объёмов данных, управление изменениями данных, обеспечение согласованности при отказах и конкурентном доступе, а также гарантия высокой доступности сервисов.
Подобные приложения обычно строятся из стандартных строительных блоков, которые обеспечивают часто необходимую функциональность. Например, многим приложениям требуется:
- Сохранять данные таким образом, чтобы они сами или другие приложения могли найти их позже (базы данных)
- Запоминать результат дорогостоящей операции для ускорения чтения (кеши)
- Позволять пользователям искать данные по ключевым словам или фильтровать их различными способами (поисковые индексы)
- Обрабатывать события и изменения данных сразу после их возникновения (потоковая обработка)
- Периодически обрабатывать большой объём накопленных данных (пакетная обработка)
При создании приложения мы обычно берём несколько программных систем или сервисов, таких как базы данных или API, и связываем их с помощью кода приложения. Если вы делаете именно то, для чего были спроектированы системы данных, то этот процесс может быть довольно простым.
Однако по мере усложнения вашего приложения возникают сложности. Существует множество систем баз данных с разными характеристиками, подходящих для различных целей — как выбрать, какую использовать? Есть различные подходы к кешированию, несколько способов построения поисковых индексов и так далее — как оценить их компромиссы? Вам необходимо выяснить, какие инструменты и подходы наиболее подходят для конкретной задачи, и может быть сложно объединить инструменты, когда нужно сделать что-то, что один инструмент не может выполнить самостоятельно.
Эта книга представляет собой руководство, которое поможет вам принимать решения о том, какие технологии использовать и как их объединять. Как вы увидите, не существует подхода, который был бы принципиально лучше других — всё имеет свои плюсы и минусы. С помощью этой книги вы научитесь задавать правильные вопросы для оценки и сравнения систем данных, чтобы определить, какой подход наилучшим образом удовлетворит потребности вашего конкретного приложения.
Мы начнём наше путешествие с рассмотрения некоторых способов использования данных в современных организациях. Многие идеи здесь берут начало в корпоративном программном обеспечении (то есть в программных потребностях и инженерных практиках крупных организаций, таких как большие корпорации и правительства), поскольку исторически только крупные организации располагали большими объёмами данных, требующими сложных технических решений. Если объём ваших данных достаточно мал, вы можете просто хранить их в электронной таблице! Однако в последнее время стало обычным делом для небольших компаний и стартапов управлять большими объёмами данных и создавать системы интенсивной обработки данных.
Одной из ключевых проблем систем данных является то, что разным людям нужно делать с данными совершенно разные вещи. Если вы работаете в компании, у вас и вашей команды будет один набор приоритетов, в то время как у другой команды могут быть совершенно иные цели, даже если вы работаете с одним и тем же набором данных! Более того, эти цели могут быть явно не сформулированы, что может привести к недопониманию и разногласиям относительно правильного подхода.
Чтобы помочь вам понять, какой выбор можно сделать, эта глава сравнивает несколько контрастирующих концепций и исследует их компромиссы:
- различие между операционными и аналитическими системами («Аналитические против операционных систем»);
- плюсы и минусы облачных сервисов и самостоятельно размещаемых систем («Облако против самостоятельного размещения»);
- когда переходить от односерверных систем к распределённым системам («Распределённые против односерверных систем»); и
- балансирование потребностей бизнеса и прав пользователя («Системы данных, право и общество»).
Кроме того, эта глава предоставит вам терминологию, которая понадобится нам для остальной части книги.
Терминология: фронтенд и бэкенд
Большая часть того, что мы будем обсуждать в этой книге, относится к разработке серверной части (backend development). Поясним этот термин: для веб-приложений клиентский код (который выполняется в веб-браузере) называется фронтендом, а серверный код, который обрабатывает запросы пользователей, известен как бэкенд. Мобильные приложения схожи с фронтендами в том, что они предоставляют пользовательские интерфейсы, которые часто взаимодействуют через Интернет с серверным бэкендом. Фронтенды иногда управляют данными локально на устройстве пользователя [2], но наибольшие сложности инфраструктуры данных часто возникают в бэкенде: фронтенду нужно обрабатывать только данные одного пользователя, тогда как бэкенд управляет данными от имени всех пользователей.
Серверный сервис часто доступен через HTTP (иногда WebSocket); он обычно состоит из некоторого кода приложения, который читает и записывает данные в одну или несколько баз данных, и иногда взаимодействует с дополнительными системами данных, такими как кеши или очереди сообщений (которые мы можем совокупно называть инфраструктурой данных). Код приложения часто является статeless (то есть когда он заканчивает обработку одного HTTP-запроса, он забывает всё об этом запросе), и любая информация, которая должна сохраняться от одного запроса к другому, должна храниться либо на клиенте, либо в серверной инфраструктуре данных.
Аналитические против операционных систем
Если вы работаете с системами данных в корпоративной среде, вы, вероятно, столкнётесь с несколькими различными типами людей, которые работают с данными. Первый тип — это серверные разработчики (backend engineers), которые создают сервисы для обработки запросов на чтение и обновление данных; эти сервисы часто обслуживают внешних пользователей, либо напрямую, либо опосредованно через другие сервисы (см. «Микросервисы и бессерверная архитектура»). Иногда сервисы предназначены для внутреннего использования другими частями организации.
Помимо команд, управляющих серверными сервисами, обычно существуют две другие группы людей, которым требуется доступ к данным организации: бизнес-аналитики, которые составляют отчёты о деятельности организации, чтобы помочь руководству принимать более обоснованные решения (бизнес-аналитика или BI), и специалисты по данным (data scientists), которые ищут новые закономерности в данных или создают пользовательские функции продуктов, основанные на анализе данных и машинном обучении/ИИ (например, рекомендации «люди, купившие X, также покупали Y» на сайте электронной коммерции, предиктивная аналитика, такая как оценка рисков или фильтрация спама, и ранжирование результатов поиска).
Хотя бизнес-аналитики и специалисты по данным склонны использовать разные инструменты и работать по-разному, у них есть общие черты: оба выполняют аналитику, что означает изучение данных, которые сгенерировали пользователи и серверные сервисы, но обычно они не изменяют эти данные (за исключением, возможно, исправления ошибок). Они могут создавать производные наборы данных, в которых исходные данные были каким-то образом обработаны. Это привело к разделению на два типа систем — различие, которое мы будем использовать на протяжении всей этой книги:S
- Операционные системы состоят из серверных сервисов и инфраструктуры данных, где данные создаются, например, при обслуживании внешних пользователей. Здесь код приложения одновременно читает и изменяет данные в своих базах данных на основе действий, выполняемых пользователями.
- Аналитические системы обслуживают потребности бизнес-аналитиков и специалистов по данным. Они содержат копию данных из операционных систем только для чтения и оптимизированы для типов обработки данных, необходимых для аналитики.
Как мы увидим в следующем разделе, операционные и аналитические системы часто разделяют по веским причинам. По мере развития этих систем появились две новые специализированные роли: инженеры данных (data engineers) и аналитические инженеры (analytics engineers). Инженеры данных — это люди, которые знают, как интегрировать операционные и аналитические системы, и которые несут ответственность за инфраструктуру данных организации в целом [3]. Аналитические инженеры моделируют и преобразуют данные, чтобы сделать их более полезными для бизнес-аналитиков и специалистов по данным в организации [4].
Многие инженеры специализируются либо на операционной, либо на аналитической стороне. Однако эта книга охватывает как операционные, так и аналитические системы данных, поскольку обе играют важную роль в жизненном цикле данных внутри организации. Мы подробно изучим инфраструктуру данных, которая используется для предоставления сервисов как внутренним, так и внешним пользователям, чтобы вы могли лучше работать с коллегами по другую сторону этого разделения.
Характеристика транзакционной обработки и аналитики
В ранние дни обработки бизнес-данных запись в базу данных обычно соответствовала коммерческой транзакции: совершению продажи, размещению заказа у поставщика, выплате зарплаты сотруднику и т.д. Когда базы данных расширились на области, не связанные с движением денег, термин транзакция тем не менее закрепился и стал обозначать группу операций чтения и записи, образующих логическую единицу.
Примечание
Глава 8 подробно рассматривает, что мы понимаем под транзакцией. В данной главе этот термин используется в широком смысле для обозначения операций чтения и записи с низкой задержкой.
Хотя базы данных стали использоваться для множества различных видов данных — записей в социальных сетях, ходов в игре, контактов в адресной книге и многих других — основной паттерн доступа оставался схожим с обработкой бизнес-транзакций. Операционная система обычно ищет небольшое количество записей по некоторому ключу (это называется точечным запросом). Записи вставляются, обновляются или удаляются на основе пользовательского ввода. Поскольку эти приложения являются интерактивными, данный паттерн доступа стал известен как оперативная транзакционная обработка (OLTP, online transaction processing).
Однако базы данных также стали всё чаще использоваться для аналитики, которая имеет совершенно иные паттерны доступа по сравнению с OLTP. Обычно аналитический запрос сканирует огромное количество записей и вычисляет агрегированную статистику (такую как количество, сумма или среднее значение), а не возвращает отдельные записи пользователю. Например, бизнес-аналитик в сети супермаркетов может захотеть ответить на такие аналитические запросы:
- Какой была общая выручка каждого из наших магазинов в январе?
- На сколько больше бананов, чем обычно, мы продали во время последней акции?
- Какой бренд детского питания чаще всего покупают вместе с подгузниками бренда X?
Отчёты, получаемые в результате подобных запросов, важны для бизнес-аналитики и помогают руководству решить, что делать дальше. Чтобы отличить этот паттерн использования баз данных от транзакционной обработки, его назвали оперативной аналитической обработкой (OLAP, online analytic processing) [5]. Различие между OLTP и аналитикой не всегда чётко определено, но некоторые типичные характеристики приведены в таблице 1-1.
Таблица 1-1. Сравнение характеристик операционных и аналитических систем
| Свойство | Операционные системы (OLTP) | Аналитические системы (OLAP) |
|---|---|---|
| Основной паттерн чтения | Точечные запросы (извлечение отдельных записей по ключу) | Агрегация по большому количеству записей |
| Основной паттерн записи | Создание, обновление и удаление отдельных записей | Массовый импорт (ETL) или поток событий |
| Пример использования человеком | Конечный пользователь веб/мобильного приложения | Внутренний аналитик для поддержки принятия решений |
| Пример машинного использования | Проверка авторизации действия | Выявление мошенничества/паттернов злоупотреблений |
| Тип запросов | Фиксированный набор запросов, предопределённых приложением | Аналитик может выполнять произвольные запросы |
| Что представляют данные | Последнее состояние данных (текущий момент времени) | История событий, произошедших с течением времени |
| Размер набора данных | Гигабайты — терабайты | Терабайты — петабайты |
Примечание
Значение слова online в OLAP неясно; вероятно, оно относится к тому факту, что запросы предназначены не только для предопределённых отчётов, но и для того, чтобы аналитики использовали OLAP-систему интерактивно для исследовательских запросов.
В операционных системах пользователям обычно не разрешается создавать произвольные SQL-запросы и выполнять их в базе данных, поскольку это потенциально позволило бы им читать или изменять данные, к которым у них нет разрешения на доступ. Более того, они могут написать запросы, которые дорого выполнять, и таким образом повлиять на производительность базы данных для других пользователей. По этим причинам OLTP-системы в основном выполняют фиксированный набор запросов, которые встроены в код приложения, и используют единичные произвольные запросы только изредка для обслуживания или устранения неполадок. С другой стороны, аналитические базы данных обычно предоставляют своим пользователям свободу написания произвольных SQL-запросов вручную или автоматической генерации запросов с помощью инструментов визуализации данных или дашбордов, таких как Tableau, Looker или Microsoft Power BI.
Существует также тип систем, которые спроектированы для аналитических нагрузок (запросы, агрегирующие множество записей), но встроены в пользовательские продукты. Эта категория известна как продуктовая аналитика или аналитика в реальном времени, и системы, предназначенные для такого использования, включают Pinot, Druid и ClickHouse [6].
Хранилища данных
Поначалу одни и те же базы данных использовались как для транзакционной обработки, так и для аналитических запросов. SQL оказался довольно гибким в этом отношении: он хорошо работает для обоих типов запросов. Тем не менее в конце 1980-х — начале 1990-х годов наметилась тенденция: компании перестали использовать свои OLTP-системы для аналитических целей и стали выполнять аналитику в отдельной системе баз данных. Эта отдельная база данных получила название хранилище данных (data warehouse).
Крупное предприятие может иметь десятки, даже сотни систем оперативной транзакционной обработки: системы, обеспечивающие работу клиентского веб-сайта, управляющие кассовыми системами в физических магазинах, отслеживающие товарные запасы на складах, планирующие маршруты транспортных средств, управляющие поставщиками, администрирующие сотрудников и выполняющие множество других задач. Каждая из этих систем сложна и требует команды людей для её поддержки, поэтому эти системы в итоге работают в основном независимо друг от друга.
Обычно нежелательно, чтобы бизнес-аналитики и специалисты по данным напрямую обращались к этим OLTP-системам по нескольким причинам:
- интересующие данные могут быть распределены между множественными операционными системами, что затрудняет объединение этих наборов данных в едином запросе (проблема, известная как изолированность данных, data silos);
- типы схем и компоновки данных, которые хороши для OLTP, менее подходят для аналитики (см. «Звёзды и снежинки: схемы для аналитики»);
- аналитические запросы могут быть довольно затратными, и их выполнение в OLTP-базе данных повлияло бы на производительность для других пользователей; и
- OLTP-системы могут находиться в отдельной сети, к которой пользователям запрещён прямой доступ по соображениям безопасности или соответствия требованиям.
Хранилище данных, напротив, представляет собой отдельную базу данных, которую аналитики могут запрашивать сколько угодно, не влияя на OLTP-операции [7]. Как мы увидим в главе 4, хранилища данных часто хранят данные способом, очень отличающимся от OLTP-баз данных, чтобы оптимизировать типы запросов, характерные для аналитики.
Хранилище данных содержит копию данных только для чтения из всех различных OLTP-систем компании. Данные извлекаются из OLTP-баз данных (с помощью периодических выгрузок данных или непрерывного потока обновлений), преобразуются в схему, удобную для анализа, очищаются, а затем загружаются в хранилище данных. Этот процесс помещения данных в хранилище данных известен как извлечение-преобразование-загрузка (Extract–Transform–Load, ETL) и проиллюстрирован на рисунке 1-1. Иногда порядок этапов преобразования и загрузки меняется местами (то есть преобразование выполняется в хранилище данных после загрузки), что приводит к ELT.
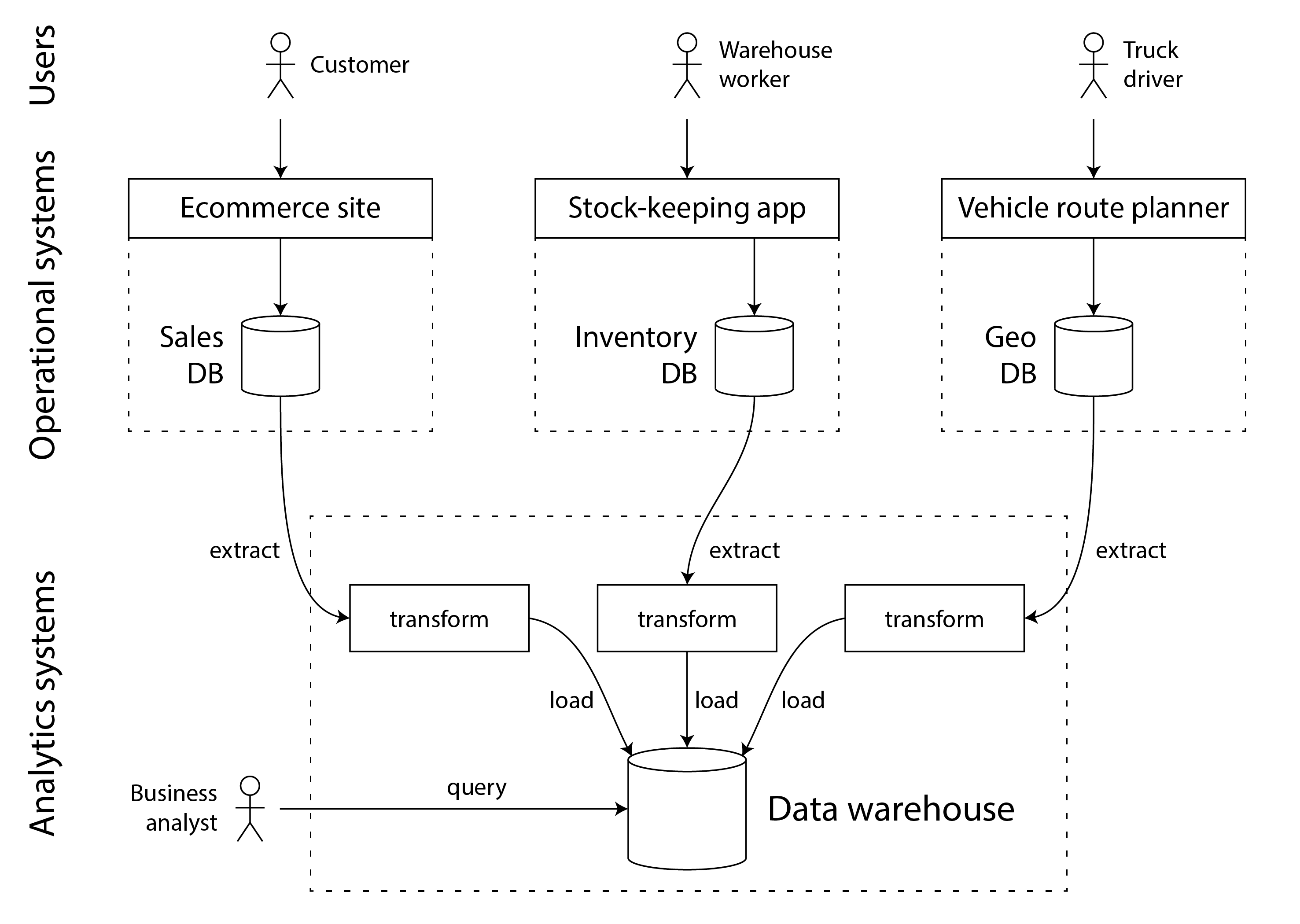
Рисунок 1-1. Упрощённая схема ETL в хранилище данных.
В некоторых случаях источниками данных для ETL-процессов являются внешние SaaS-продукты, такие как системы управления взаимоотношениями с клиентами (CRM), email-маркетинга или обработки платежей по кредитным картам. В таких случаях у вас нет прямого доступа к исходной базе данных, поскольку она доступна только через API поставщика программного обеспечения. Перенос данных из этих внешних систем в ваше собственное хранилище данных может обеспечить анализ, который невозможен через SaaS API. ETL для SaaS API часто реализуется специализированными сервисами подключения данных, такими как Fivetran, Singer или AirByte.
Некоторые системы баз данных предлагают гибридную транзакционно-аналитическую обработку (HTAP, hybrid transactional/analytic processing), которая нацелена на обеспечение OLTP и аналитики в единой системе без необходимости ETL из одной системы в другую [8, 9]. Однако многие HTAP-системы внутренне состоят из OLTP-системы, связанной с отдельной аналитической системой, скрытой за общим интерфейсом — поэтому различие между ними остаётся важным для понимания работы этих систем.
Более того, хотя HTAP существует, разделение между транзакционными и аналитическими системами остаётся обычным делом из-за их различных целей и требований. В частности, считается хорошей практикой, чтобы каждая операционная система имела собственную базу данных (см. «Микросервисы и бессерверная архитектура»), что приводит к сотням отдельных операционных баз данных; с другой стороны, предприятие обычно имеет единое хранилище данных, чтобы бизнес-аналитики могли объединять данные из нескольких операционных систем в одном запросе.
Поэтому HTAP не заменяет хранилища данных. Скорее, это полезно в сценариях, где одному приложению необходимо как выполнять аналитические запросы, сканирующие большое количество строк, так и читать и обновлять отдельные записи с низкой задержкой. Например, обнаружение мошенничества может включать подобные нагрузки [10].
Разделение между операционными и аналитическими системами является частью более широкой тенденции: по мере роста требовательности нагрузок системы становятся более специализированными и оптимизированными для конкретных типов работ. Универсальные системы могут комфортно обрабатывать небольшие объёмы данных, но чем больше масштаб, тем более специализированными становятся системы [11].
От хранилища данных к озеру данных
Хранилище данных часто использует реляционную модель данных, к которой обращаются через SQL (см. главу 3), возможно, с применением специализированного программного обеспечения бизнес-аналитики. Эта модель хорошо работает для типов запросов, которые необходимо выполнять бизнес-аналитикам, но она менее подходит для потребностей специалистов по данным, которым может потребоваться выполнять такие задачи, как:
- Преобразование данных в форму, подходящую для обучения модели машинного обучения; часто это требует превращения строк и столбцов таблицы базы данных в вектор или матрицу числовых значений, называемых признаками (features). Процесс выполнения такого преобразования способом, который максимизирует производительность обученной модели, называется разработкой признаков (feature engineering), и часто требует специального кода, который сложно выразить с помощью SQL.
- Обработка текстовых данных (например, отзывов о продукте) с использованием техник обработки естественного языка для извлечения из них структурированной информации (например, настроения автора или упоминаемых тем). Аналогично, им может потребоваться извлекать структурированную информацию из фотографий с помощью техник компьютерного зрения.
Хотя предпринимались попытки добавить операторы машинного обучения в SQL-модель данных [12] и построить эффективные системы машинного обучения поверх реляционной основы [13], многие специалисты по данным предпочитают не работать в реляционной базе данных вроде хранилища данных. Вместо этого многие предпочитают использовать библиотеки анализа данных Python, такие как pandas и scikit-learn, языки статистического анализа вроде R и распределённые аналитические фреймворки, такие как Spark [14]. Мы обсудим их подробнее в разделе «Датафреймы, матрицы и массивы».
Следовательно, организации сталкиваются с необходимостью предоставления данных в форме, подходящей для использования специалистами по данным. Ответом является озеро данных (data lake): централизованное хранилище данных, которое содержит копию любых данных, которые могут быть полезны для анализа, полученных из операционных систем посредством ETL-процессов. Отличие от хранилища данных состоит в том, что озеро данных просто содержит файлы, не навязывая какого-либо определённого формата файлов или модели данных. Файлы в озере данных могут представлять собой коллекции записей базы данных, закодированные с использованием формата файлов, такого как Avro или Parquet (см. главу 5), но они равным образом могут содержать текст, изображения, видео, показания датчиков, разреженные матрицы, векторы признаков, последовательности генома или любые другие виды данных [15]. Помимо большей гибкости, это также часто дешевле реляционного хранения данных, поскольку озеро данных может использовать товарное файловое хранилище, такое как объектные хранилища (см. «Облачно-ориентированная архитектура систем»).
ETL-процессы были обобщены до конвейеров данных (data pipelines), и в некоторых случаях озеро данных стало промежуточной остановкой на пути от операционных систем к хранилищу данных. Озеро данных содержит данные в «сыром» виде, созданном операционными системами, без преобразования в схему реляционного хранилища данных. Этот подход имеет преимущество в том, что каждый потребитель данных может преобразовать сырые данные в форму, которая лучше всего подходит для его нужд. Это получило название принципа суши: «сырые данные лучше» [16].
Помимо загрузки данных из озера данных в отдельное хранилище данных, также возможно выполнять типичные задачи хранилища данных (SQL-запросы и бизнес-аналитику) непосредственно на файлах в озере данных, наряду с нагрузками науки о данных/машинного обучения. Эта архитектура известна как дом-озеро данных (data lakehouse) и требует движка выполнения запросов и слоя метаданных (например, управления схемами), которые расширяют файловое хранилище озера данных [17]. Apache Hive, Spark SQL, Presto и Trino являются примерами такого подхода.
За пределами озера данных
По мере развития аналитических практик организации всё больше внимания уделяют управлению и эксплуатации аналитических систем и конвейеров данных, что отражено, например, в манифесте DataOps [18]. Частью этого являются вопросы управления, конфиденциальности и соблюдения требований регулирования, таких как GDPR и CCPA, которые мы обсуждаем в разделах «Системы данных, право и общество» и [Ссылка будет добавлена].
Более того, аналитические данные всё чаще предоставляются не только в виде файлов и реляционных таблиц, но и в виде потоков событий (см. [Ссылка будет добавлена]). При файловом анализе данных можно периодически (например, ежедневно) повторно запускать анализ для реагирования на изменения в данных, но потоковая обработка позволяет аналитическим системам реагировать на события гораздо быстрее — в течение секунд. В зависимости от приложения и его чувствительности ко времени подход потоковой обработки может быть ценным, например, для выявления и блокировки потенциально мошеннических или злоупотребительных действий.
В некоторых случаях результаты работы аналитических систем предоставляются операционным системам (процесс, иногда называемый обратным ETL [19]). Например, модель машинного обучения, обученная на данных в аналитической системе, может быть развёрнута в продакшене для генерации рекомендаций конечным пользователям, таких как «люди, купившие X, также покупали Y». Такие развёрнутые результаты работы аналитических систем также известны как продукты данных (data products) [20]. Модели машинного обучения можно развертывать в операционных системах с использованием специализированных инструментов, таких как TFX, Kubeflow или MLflow.
Системы записи и производные данные
В связи с различием между операционными и аналитическими системами в этой книге также проводится разграничение между системами записи и системами производных данных. Эти термины полезны, поскольку могут помочь прояснить поток данных через систему:
Системы записи
- Система записи, также известная как источник истины (source of truth), содержит авторитетную или каноническую версию некоторых данных. Когда поступают новые данные, например в виде пользовательского ввода, они сначала записываются сюда. Каждый факт представлен ровно один раз (представление обычно нормализовано; см. «Нормализация, денормализация и соединения»). Если есть какое-либо расхождение между другой системой и системой записи, то значение в системе записи является (по определению) правильным.
Системы производных данных
- Данные в производной системе являются результатом взятия существующих данных из другой системы и их преобразования или обработки каким-либо образом. Если вы потеряете производные данные, вы можете воссоздать их из первоначального источника. Классический пример — кеш: данные могут обслуживаться из кеша, если они там присутствуют, но если кеш не содержит того, что вам нужно, можно обратиться к исходной базе данных. В эту категорию также попадают денормализованные значения, индексы, материализованные представления, преобразованные представления данных и модели, обученные на наборе данных.
Технически говоря, производные данные избыточны в том смысле, что они дублируют существующую информацию. Однако они часто необходимы для достижения хорошей производительности запросов на чтение. Из одного источника можно получить несколько различных наборов данных, что позволяет рассматривать данные с разных «точек зрения».
Аналитические системы обычно являются системами производных данных, поскольку они потребляют данные, созданные в других местах. Операционные сервисы могут содержать смесь систем записи и систем производных данных. Системы записи — это основные базы данных, в которые данные записываются в первую очередь, тогда как системы производных данных — это индексы и кеши, которые ускоряют обычные операции чтения, особенно для запросов, на которые система записи не может ответить эффективно.
Большинство баз данных, механизмов хранения и языков запросов не являются по своей природе системой записи или производной системой. База данных — это просто инструмент: как вы его используете, зависит от вас. Различие между системой записи и системой производных данных зависит не от инструмента, а от того, как вы его используете в своём приложении. Четко определив, какие данные производятся из каких других данных, вы можете внести ясность в иначе запутанную архитектуру системы.
Когда данные в одной системе получены из другой системы, необходим процесс обновления производных данных при изменении первоначальных данных в системе записи. К сожалению, многие базы данных спроектированы исходя из предположения, что вашему приложению потребуется работать только с одной базой данных, и они не упрощают интеграцию нескольких систем для распространения подобных обновлений. В разделе [Ссылка будет добавлена] мы обсудим подходы к интеграции данных, которые позволяют объединять несколько систем данных для решения задач, недоступных одной системе.
На этом завершается наше сравнение аналитических и операционных систем. В следующем разделе мы рассмотрим ещё один компромисс, который вы, возможно, уже видели неоднократно обсуждаемым.
Облачные решения против собственных серверов
В любом деле, которым занимается организация, одним из первых встаёт вопрос: следует ли делать это собственными силами или отдать на аутсорсинг? Разрабатывать самим или покупать готовое решение?
В конечном счёте, это вопрос бизнес-приоритетов. Общепринятая управленческая мудрость гласит, что вещи, составляющие основную компетенцию или конкурентное преимущество вашей организации, следует делать собственными силами, в то время как второстепенные, рутинные или обычные задачи лучше поручить внешнему поставщику [21]. Для наглядности возьмём крайний пример: большинство компаний не вырабатывают собственное электричество (если только они не являются энергетической компанией, и не считая аварийного резервного питания), поскольку дешевле покупать электричество из общей сети.
В случае с программным обеспечением необходимо принять два важных решения: кто будет разрабатывать ПО и кто будет его развёртывать. Существует целый спектр возможностей, которые в разной степени передают каждое из этих решений на аутсорсинг, как показано на рисунке 1-2. На одном полюсе находится индивидуальное ПО, которое вы разрабатываете и эксплуатируете собственными силами; на другом — широко используемые облачные сервисы или продукты типа «программное обеспечение как услуга» (SaaS), которые реализуются и управляются внешним поставщиком, а вы получаете к ним доступ только через веб-интерфейс или API.

Рисунок 1-2. Спектр типов программного обеспечения и его эксплуатации.
Промежуточный вариант — готовое ПО (с открытым исходным кодом или коммерческое), которое вы размещаете самостоятельно, то есть развёртываете своими силами — например, если вы скачиваете MySQL и устанавливаете его на контролируемом вами сервере. Это может быть ваше собственное оборудование (часто называемое локальным размещением, даже если сервер фактически находится в арендованной стойке дата-центра, а не буквально в ваших помещениях) или виртуальная машина в облаке (инфраструктура как услуга, Infrastructure as a Service, IaaS). На этом спектре есть ещё больше промежуточных точек, например, использование ПО с открытым исходным кодом в модифицированной версии.
Отдельно от этого спектра стоит вопрос способа развёртывания сервисов — в облаке или локально, например, используете ли вы систему оркестрации вроде Kubernetes. Однако выбор инструментов развёртывания выходит за рамки этой книги, поскольку другие факторы оказывают большее влияние на архитектуру систем данных.
Плюсы и минусы облачных сервисов
Использование облачного сервиса вместо самостоятельного запуска аналогичного ПО фактически передаёт управление этим ПО облачному провайдеру. Есть веские аргументы как за, так и против облачных сервисов. Поставщики облачных услуг утверждают, что использование их сервисов экономит время и деньги, а также позволяет работать быстрее по сравнению с созданием собственной инфраструктуры.
Действительно ли облачный сервис окажется дешевле и проще в использовании, чем самостоятельное размещение, во многом зависит от ваших навыков и нагрузки на системы. Если у вас уже есть опыт настройки и эксплуатации необходимых систем, и если ваша нагрузка достаточно предсказуема (то есть количество требуемых машин не колеблется кардинально), то зачастую дешевле приобрести собственные серверы и запускать ПО на них самостоятельно [22, 23].
С другой стороны, если вам нужна система, которую вы пока не умеете развёртывать и эксплуатировать, то принятие облачного сервиса зачастую проще и быстрее, чем изучение управления системой собственными силами. Если приходится нанимать и обучать персонал специально для поддержки и эксплуатации системы, это может обойтись очень дорого. Команда по эксплуатации нужна и при использовании облака (см. «Эксплуатация в эпоху облачных технологий»), но передача базового системного администрирования на аутсорсинг может освободить вашу команду для решения более высокоуровневых задач.
Когда вы передаёте управление системой компании, специализирующейся на предоставлении этого сервиса, это потенциально может привести к лучшему качеству обслуживания, поскольку провайдер накапливает экспертизу в области эксплуатации, обслуживая множество клиентов. С другой стороны, при самостоятельном управлении сервисом вы можете настроить и оптимизировать его под особенности вашей конкретной нагрузки; вряд ли облачный сервис будет готов выполнить подобную настройку специально для вас.
Облачные сервисы особенно ценны, когда нагрузка на ваши системы сильно колеблется во времени. Если вы подготавливаете оборудование для работы с пиковой нагрузкой, но вычислительные ресурсы простаивают большую часть времени, система становится менее экономически эффективной. В такой ситуации облачные сервисы имеют преимущество, поскольку упрощают масштабирование вычислительных ресурсов в зависимости от изменений в спросе.
Например, аналитические системы часто имеют крайне переменную нагрузку: для быстрого выполнения большого аналитического запроса требуется одновременная работа множества вычислительных ресурсов, но после завершения запроса эти ресурсы простаивают до следующего запроса пользователя. Заранее определённые запросы (например, для ежедневных отчётов) можно поставить в очередь и запланировать для выравнивания нагрузки, но для интерактивных запросов действует правило: чем быстрее вы хотите их выполнить, тем более переменной становится рабочая нагрузка. Если ваш набор данных настолько велик, что для быстрого запроса требуются значительные вычислительные ресурсы, использование облака может сэкономить деньги, поскольку неиспользуемые ресурсы можно вернуть провайдеру, а не оставлять простаивать. Для небольших наборов данных эта разница менее существенна.
Основной недостаток облачных сервисов — отсутствие контроля над ними:
- Если сервису не хватает нужной вам функции, остается только вежливо попросить поставщика добавить её; обычно вы не можете реализовать её самостоятельно.
- При сбое сервиса остается только ждать его восстановления.
- Если вы используете сервис способом, который вызывает ошибку или проблемы с производительностью, диагностировать проблему будет сложно. При работе с ПО, которое вы запускаете сами, можно получить метрики производительности и отладочную информацию от операционной системы, изучить журналы сервера, но при использовании сервиса поставщика доступ к этим внутренним данным обычно отсутствует.
- Кроме того, если сервис прекращает работу или становится неоправданно дорогим, либо поставщик решает изменить продукт нежелательным для вас образом, вы остаетесь на их милости — продолжение использования старой версии ПО обычно невозможно, поэтому придется мигрировать на альтернативный сервис [24]. Этот риск снижается при наличии альтернативных сервисов с совместимым API, однако для многих облачных сервисов стандартные API отсутствуют, что повышает стоимость смены поставщика и создает проблему привязки к конкретному поставщику (vendor lock-in).
- Облачному провайдеру необходимо доверять обеспечение безопасности данных, что может усложнить процесс соблюдения требований конфиденциальности и безопасности.
Несмотря на все эти риски, среди организаций становится всё более популярным создание новых приложений поверх облачных сервисов или принятие гибридного подхода, при котором облачные сервисы используются для отдельных аспектов системы. Однако облачные сервисы не заменят полностью все внутренние системы данных: многие старые системы появились до эры облачных технологий, а для любых сервисов со специфическими требованиями, которые существующие облачные решения не могут удовлетворить, внутренние системы остаются необходимыми. Например, приложения, критичные к задержкам, такие как высокочастотная торговля, требуют полного контроля над оборудованием.
Облачно-ориентированная архитектура систем
Помимо иной экономической модели (подписка на сервис вместо покупки оборудования и лицензирования ПО для запуска на нём), развитие облачных технологий также оказало глубокое влияние на техническую реализацию систем данных. Термин облачно-ориентированный (cloud-native) используется для описания архитектуры, спроектированной с учётом возможностей облачных сервисов.
В принципе практически любое ПО, которое можно размещать самостоятельно, может также предоставляться как облачный сервис, и действительно, управляемые сервисы теперь доступны для многих популярных систем данных. Однако системы, изначально спроектированные как облачно-ориентированные, демонстрируют ряд преимуществ: лучшую производительность на том же оборудовании, более быстрое восстановление после сбоев, возможность оперативно масштабировать вычислительные ресурсы в соответствии с нагрузкой и поддержку больших наборов данных [25, 26, 27]. В таблице 1-2 приведены примеры систем обоих типов.
Таблица 1-2. Примеры самостоятельно размещаемых и облачно-ориентированных систем баз данных
| Категория | Самостоятельно размещаемые системы | Облачно-ориентированные системы |
|---|---|---|
| Операционные/OLTP | MySQL, PostgreSQL, MongoDB | AWS Aurora [25], Azure SQL DB Hyperscale [26], Google Cloud Spanner |
| Аналитические/OLAP | Teradata, ClickHouse, Spark | Snowflake [27], Google BigQuery, Azure Synapse Analytics |
Многоуровневость облачных сервисов
Большинство систем данных, размещаемых самостоятельно, имеют очень простые системные требования: они работают на обычной операционной системе вроде Linux или Windows, сохраняют данные в виде файлов в файловой системе и обмениваются информацией через стандартные сетевые протоколы, такие как TCP/IP. Некоторые системы зависят от специального оборудования — графических процессоров (для машинного обучения) или сетевых интерфейсов RDMA, но в целом самостоятельно размещаемое ПО использует очень универсальные вычислительные ресурсы: процессор, оперативную память, файловую систему и IP-сеть.
В облачной среде такое ПО можно запускать в среде «Инфраструктура как услуга» (Infrastructure-as-a-Service), используя одну или несколько виртуальных машин (или экземпляров) с определённым выделением процессоров, памяти, дискового пространства и пропускной способности сети. По сравнению с физическими машинами облачные экземпляры можно подготовить быстрее, и они представлены в большем разнообразии размеров, но в остальном они схожи с традиционным компьютером: на них можно запускать любое ПО по выбору, но администрировать его придётся самостоятельно.
Напротив, ключевая идея облачно-ориентированных сервисов заключается в использовании не только вычислительных ресурсов, управляемых операционной системой, но и в построении решений более высокого уровня на основе низкоуровневых облачных сервисов. Например:
- Сервисы объектного хранилища, такие как Amazon S3, Azure Blob Storage и Cloudflare R2, предназначены для хранения больших файлов. Они предоставляют более ограниченные API по сравнению с обычной файловой системой (базовые операции чтения и записи файлов), но имеют преимущество в том, что скрывают лежащие в основе физические машины: сервис автоматически распределяет данные между множеством машин, так что не нужно беспокоиться об исчерпании дискового пространства на какой-либо одной машине. Даже при полном отказе некоторых машин или их дисков данные не теряются.
- Многие другие сервисы, в свою очередь, строятся поверх объектного хранилища и других облачных сервисов: например, Snowflake — это облачная аналитическая база данных (хранилище данных), которая использует S3 для хранения данных [27], а некоторые другие сервисы, в свою очередь, строятся поверх Snowflake.
Как и всегда при работе с абстракциями в программировании, не существует единственно правильного ответа на вопрос о том, что следует использовать. Как правило, абстракции более высокого уровня ориентированы на конкретные случаи применения. Если ваши потребности соответствуют ситуациям, для которых спроектирована высокоуровневая система, использование существующей высокоуровневой системы, вероятно, обеспечит то, что вам нужно, с гораздо меньшими хлопотами, чем её создание с нуля из низкоуровневых систем. С другой стороны, если не существует высокоуровневой системы, отвечающей вашим потребностям, единственным вариантом остаётся её создание собственными силами из низкоуровневых компонентов.
Разделение хранилища и вычислений
В традиционных вычислительных системах дисковое хранилище считается надёжным (мы предполагаем, что записанные на диск данные не будут потеряны). Для защиты от сбоя отдельного жёсткого диска часто используется RAID (избыточный массив независимых дисков), который поддерживает копии данных на нескольких дисках, подключённых к одной машине. RAID может выполняться как аппаратно, так и программно операционной системой и остаётся прозрачным для приложений, обращающихся к файловой системе.
В облачной среде вычислительные экземпляры (виртуальные машины) также могут иметь подключённые локальные диски, но облачно-ориентированные системы обычно рассматривают эти диски скорее как временный кеш, чем как долговременное хранилище. Это связано с тем, что локальный диск становится недоступным при сбое соответствующего экземпляра или при его замене на больший или меньший (на другой физической машине) для адаптации к изменениям нагрузки.
В качестве альтернативы локальным дискам облачные сервисы также предлагают виртуальное дисковое хранилище, которое можно отключить от одного экземпляра и подключить к другому (Amazon EBS, управляемые диски Azure и постоянные диски в Google Cloud). Такой виртуальный диск на самом деле не является физическим диском, а представляет собой облачный сервис, предоставляемый отдельным набором машин, который эмулирует поведение диска (блочное устройство, где каждый блок обычно имеет размер 4 КБ). Эта технология позволяет запускать традиционное дисковое ПО в облаке, но эмуляция блочного устройства вносит накладные расходы, которых можно избежать в системах, изначально спроектированных для облака [25]. Это также делает приложение очень чувствительным к сбоям сети, поскольку каждая операция ввода-вывода на виртуальном блочном устройстве фактически является сетевым вызовом [28].
Для решения этой проблемы облачно-ориентированные сервисы обычно избегают использования виртуальных дисков и вместо этого строятся на основе специализированных сервисов хранения, оптимизированных для конкретных типов нагрузок. Сервисы объектного хранения, такие как S3, предназначены для долгосрочного хранения достаточно больших файлов размером от сотен килобайт до нескольких гигабайт. Отдельные записи или значения, хранящиеся в базе данных, обычно гораздо меньше этого размера; поэтому облачные базы данных обычно управляют более мелкими значениями в отдельном сервисе, а более крупные блоки данных (содержащие множество отдельных значений) сохраняют в объектном хранилище [26, 29]. Мы рассмотрим способы реализации этого в главе 4.
В традиционной архитектуре систем один и тот же компьютер отвечает как за хранение данных (диск), так и за вычисления (процессор и оперативная память), но в облачно-ориентированных системах эти две функции стали частично разделёнными или дезагрегированными [9, 27, 30, 31]: например, S3 только хранит файлы, а для анализа этих данных потребуется запустить код анализа где-то вне S3. Это подразумевает передачу данных по сети, что мы подробнее обсудим в разделе «Распределённые против односерверных систем».
Кроме того, облачно-ориентированные системы часто являются многопользовательскими (multitenant), что означает, что вместо выделения отдельной машины для каждого клиента данные и вычисления нескольких разных клиентов обрабатываются на одном и том же общем оборудовании одним сервисом [32]. Многопользовательский режим может обеспечить лучшее использование оборудования, более простое масштабирование и упрощённое управление для облачного провайдера, но также требует тщательной разработки для гарантии того, что активность одного клиента не повлияет на производительность или безопасность системы для других клиентов [33].
Эксплуатация в эпоху облачных технологий
Традиционно людей, управляющих серверной инфраструктурой данных организации, называли администраторами баз данных (database administrators, DBA) или системными администраторами (system administrators, sysadmins). В последнее время многие организации стараются объединить роли разработки программного обеспечения и эксплуатации в команды с общей ответственностью как за серверные сервисы, так и за инфраструктуру данных; философия DevOps направляет эту тенденцию. Инженеры надёжности сайтов (Site Reliability Engineers, SRE) — это реализация данной идеи в Google [34].
Роль эксплуатации заключается в обеспечении надёжного предоставления сервисов пользователям (включая настройку инфраструктуры и развёртывание приложений) и поддержании стабильной рабочей среды (включая мониторинг и диагностику любых проблем, которые могут повлиять на надёжность). Для самостоятельно размещаемых систем эксплуатация традиционно включает значительный объём работы на уровне отдельных машин, такой как планирование мощностей (например, мониторинг доступного дискового пространства и добавление новых дисков до его исчерпания), подготовка новых машин, перенос сервисов с одной машины на другую и установка обновлений операционной системы.
Многие облачные сервисы предоставляют API, который скрывает отдельные машины, фактически реализующие сервис. Например, облачное хранилище заменяет диски фиксированного размера тарификацией по использованию, где можно сохранять данные без предварительного планирования потребностей в мощностях, а плата взимается на основе фактически используемого пространства. Кроме того, многие облачные сервисы остаются высокодоступными даже при отказе отдельных машин (см. «Надёжность и отказоустойчивость»).
Этот переход от акцента на отдельных машинах к сервисам сопровождался изменением роли эксплуатации. Высокоуровневая цель обеспечения надёжного сервиса остаётся прежней, но процессы и инструменты эволюционировали. Философия DevOps/SRE делает больший акцент на:
- автоматизации — предпочтении повторяемых процессов разовым ручным задачам,
- предпочтении временных виртуальных машин и сервисов долго работающим серверам,
- обеспечении частых обновлений приложений,
- извлечении уроков из инцидентов, и
- сохранении знаний организации о системе даже при смене сотрудников [35].
С развитием облачных сервисов произошло разделение ролей: команды эксплуатации в инфраструктурных компаниях специализируются на деталях предоставления надёжного сервиса большому количеству клиентов, в то время как клиенты сервиса тратят минимум времени и усилий на инфраструктуру [36].
Пользователям облачных сервисов всё ещё требуется операционная деятельность, но они сосредотачиваются на других аспектах: выборе наиболее подходящего сервиса для конкретной задачи, интеграции различных сервисов между собой и переходе с одного сервиса на другой. Хотя тарификация по факту использования устраняет потребность в планировании мощностей в традиционном понимании, по-прежнему важно понимать, какие ресурсы и для каких целей используются, чтобы не тратить средства на ненужные облачные ресурсы: планирование мощностей становится финансовым планированием, а оптимизация производительности превращается в оптимизацию затрат [37]. Кроме того, у облачных сервисов действительно есть ограничения ресурсов или квоты (например, максимальное количество одновременно выполняемых процессов), которые необходимо знать и учитывать заранее, до того как вы столкнётесь с ними [38].
Внедрение облачного сервиса может быть проще и быстрее, чем эксплуатация собственной инфраструктуры, хотя и здесь есть затраты на изучение способов его использования и, возможно, обход его ограничений. Интеграция между различными сервисами становится особой проблемой, поскольку растущее число поставщиков предлагает всё более широкий спектр облачных сервисов для разных случаев использования [39, 40]. ETL (см. «Хранилища данных») — это лишь часть истории; операционные облачные сервисы также нуждаются в интеграции друг с другом. В настоящее время отсутствуют стандарты, которые упростили бы такую интеграцию, поэтому она часто требует значительных ручных усилий.
Другие эксплуатационные аспекты, которые нельзя полностью передать на аутсорсинг облачным сервисам, включают поддержание безопасности приложения и используемых им библиотек, управление взаимодействием между собственными сервисами, мониторинг нагрузки на сервисы и выяснение причин проблем, таких как снижение производительности или сбои. Хотя облачные технологии меняют роль эксплуатации, потребность в ней остаётся как никогда высокой.
Распределённые против односерверных систем
Система, включающая несколько машин, взаимодействующих через сеть, называется распределённой системой. Каждый процесс, участвующий в распределённой системе, называется узлом. Существует множество причин для создания распределённой системы:
Изначально распределённые системы
- Если приложение предполагает взаимодействие двух или более пользователей на разных устройствах, система неизбежно становится распределённой: связь между устройствами происходит через сеть.
Запросы между облачными сервисами
- Когда данные хранятся в одном сервисе, а обрабатываются в другом, их передача по сети неизбежна.
Отказоустойчивость и высокая доступность
- Если приложение должно работать даже при выходе из строя одной или нескольких машин, сети или целого дата-центра, можно использовать несколько машин для резервирования. При отказе одной машины другая берёт на себя её функции. См. «Надёжность и отказоустойчивость» и главу 6 о репликации.
Масштабируемость
- Когда объём данных или вычислительные требования превышают возможности одной машины, нагрузку распределяют между несколькими машинами. См. «Масштабируемость».
Снижение задержек
- При наличии пользователей по всему миру серверы размещают в различных регионах, чтобы каждый пользователь обслуживался ближайшим сервером. Это избавляет от необходимости ждать прохождения сетевых пакетов через полмира. См. «Описание производительности».
Эластичность
- Если нагрузка на приложение колеблется во времени, облачное развёртывание может автоматически масштабироваться в соответствии с потребностями, позволяя платить только за используемые ресурсы. Одну машину сложнее использовать эластично — её приходится готовить для пиковой нагрузки, даже когда она почти не используется.
Специализированное оборудование
- Разные части системы могут использовать оборудование, оптимизированное под конкретные задачи. Например, объектное хранилище использует машины с множеством дисков и небольшим количеством процессоров, системы анализа данных — машины с мощными процессорами и большим объёмом памяти без дисков, а системы машинного обучения — машины с графическими процессорами, которые эффективнее обычных процессоров для обучения нейронных сетей.
Соответствие законодательству
- Законы некоторых стран требуют хранения и обработки персональных данных граждан в пределах территории страны [41]. Область применения таких требований различается: иногда они касаются только медицинских или финансовых данных, иногда — более широкого спектра информации. Сервисы с пользователями в нескольких юрисдикциях вынуждены распределять данные между серверами в разных локациях.
Экологическая устойчивость
- При возможности выбирать время и место выполнения задач их можно запускать там и тогда, где доступно много возобновляемой энергии, избегая периодов перегрузки электросети. Это снижает углеродный след и позволяет использовать дешёвую электроэнергию [42, 43].
Эти причины применимы как к сервисам собственной разработки, так и к готовым решениям вроде баз данных.
Проблемы распределённых систем
Распределённые системы имеют и недостатки. Каждый запрос и вызов API, проходящий по сети, должен учитывать возможность сбоя: сеть может прерваться, сервис может быть перегружен или недоступен, поэтому любой запрос может завершиться по таймауту без получения ответа. В этом случае мы не знаем, получил ли сервис запрос, и простое повторение может быть небезопасным. Эти проблемы подробно рассматриваются в главе 9.
Хотя сети дата-центров быстры, вызов другого сервиса всё равно значительно медленнее вызова функции в том же процессе [44]. При работе с большими объёмами данных вместо передачи данных из хранилища на отдельную машину для обработки может быть быстрее перенести вычисления на машину, где уже находятся данные [45]. Больше узлов не всегда означает выше скорость: в некоторых случаях простая однопоточная программа на одном компьютере может работать значительно лучше кластера со 100+ процессорными ядрами [46].
Диагностика проблем в распределённой системе часто затруднительна: если система медленно отвечает, как понять, где именно проблема? Методы диагностики распределённых систем развиваются в рамках направления наблюдаемости (observability) [47, 48], которое включает сбор данных о работе системы и возможность их анализа для изучения как общих метрик, так и отдельных событий. Инструменты трассировки вроде OpenTelemetry, Zipkin и Jaeger позволяют отслеживать, какой клиент обращался к какому серверу для какой операции и сколько времени занял каждый вызов [49].
Базы данных предоставляют различные механизмы обеспечения согласованности данных, что рассматривается в главах 6 и 8. Однако когда у каждого сервиса своя база данных, поддержание согласованности данных между различными сервисами становится проблемой приложения. Распределённые транзакции, которые исследуются в главе 8, могут обеспечить согласованность, но редко используются в контексте микросервисов, поскольку противоречат цели независимости сервисов друг от друга, а многие базы данных их не поддерживают [50].
По всем этим причинам, если задачу можно решить на одной машине, это часто значительно проще и дешевле по сравнению с настройкой распределённой системы [23, 46, 51]. Процессоры, память и диски стали больше, быстрее и надёжнее. В сочетании с односерверными базами данных вроде DuckDB, SQLite и KùzuDB многие задачи теперь можно выполнять на одном узле. Эта тема подробнее рассматривается в главе 4.
Микросервисы и бессерверная архитектура
Наиболее распространённый способ распределения системы между несколькими машинами — разделить их на клиентов и серверы, позволив клиентам отправлять запросы серверам. Чаще всего для такого взаимодействия используется HTTP, что рассматривается в разделе «Поток данных через сервисы: REST и RPC». Один процесс может одновременно быть сервером (обрабатывая входящие запросы) и клиентом (отправляя исходящие запросы другим сервисам).
Такой подход к построению приложений традиционно называется сервис-ориентированной архитектурой (SOA); в последнее время эта идея была развита в архитектуру микросервисов [52, 53]. В такой архитектуре сервис имеет одно чётко определённое назначение (например, в случае S3 это хранение файлов); каждый сервис предоставляет API для обращения клиентов по сети, и за каждый сервис отвечает отдельная команда. Таким образом, сложное приложение можно разложить на множество взаимодействующих сервисов, каждым из которых управляет отдельная команда.
Разделение сложного программного обеспечения на множество сервисов даёт несколько преимуществ: каждый сервис можно обновлять независимо, что снижает необходимость координации между командами; каждому сервису можно выделить нужные ему аппаратные ресурсы; скрывая детали реализации за API, владельцы сервиса могут свободно изменять реализацию, не затрагивая клиентов. В плане хранения данных принято, чтобы у каждого сервиса была собственная база данных без совместного использования: общая база данных фактически сделала бы всю структуру базы частью API сервиса, что затруднило бы её изменение. Общие базы данных также могут привести к тому, что запросы одного сервиса негативно повлияют на производительность других сервисов.
С другой стороны, множество сервисов само по себе порождает сложность: каждый сервис требует инфраструктуры для развёртывания новых релизов, корректировки выделенных аппаратных ресурсов в соответствии с нагрузкой, сбора логов, мониторинга состояния сервиса и оповещения дежурного инженера в случае проблем. Фреймворки оркестрации вроде Kubernetes стали популярным способом развёртывания сервисов, поскольку обеспечивают основу для такой инфраструктуры. Тестирование сервиса в процессе разработки может усложниться, так как приходится запускать все остальные сервисы, от которых он зависит.
API микросервисов может быть сложно развивать. Клиенты, обращающиеся к API, ожидают наличия определённых полей. Разработчики могут захотеть добавить или удалить поля из API при изменении бизнес-требований, но это может привести к сбоям клиентов. Хуже того, такие сбои часто обнаруживаются только на поздних стадиях цикла разработки, когда обновлённый API сервиса развёртывается в тестовой или продакшн среде. Стандарты описания API, такие как OpenAPI и gRPC, помогают управлять взаимоотношениями между клиентскими и серверными API; это подробнее рассматривается в главе 5.
Микросервисы — это прежде всего техническое решение кадровой проблемы: они позволяют разным командам работать независимо, не координируясь друг с другом. Это ценно в крупной компании, но в небольшой компании, где команд немного, использование микросервисов, скорее всего, станет ненужными накладными расходами, и предпочтительнее реализовать приложение максимально простым способом [52].
Бессерверная архитектура или функция как услуга (FaaS) — это ещё один подход к развёртыванию сервисов, при котором управление инфраструктурой передаётся облачному провайдеру [33]. При использовании виртуальных машин необходимо явно выбирать моменты запуска или завершения работы экземпляра; в отличие от этого, в бессерверной модели облачный провайдер автоматически выделяет и освобождает аппаратные ресурсы по мере необходимости на основе входящих запросов к сервису [54]. Бессерверное развёртывание перекладывает большую часть эксплуатационной нагрузки на облачных провайдеров и обеспечивает гибкую тарификацию по использованию, а не по экземплярам машин. Для предоставления таких преимуществ многие провайдеры бессерверной инфраструктуры устанавливают временные ограничения на выполнение функций, ограничивают среды выполнения и могут страдать от медленного времени запуска при первом вызове функции. Термин «бессерверная» может вводить в заблуждение: каждая бессерверная функция всё равно выполняется на сервере, но последующие выполнения могут происходить на другом. Более того, инфраструктурные решения вроде BigQuery и различные предложения Kafka приняли терминологию «бессерверный» для обозначения того, что их сервисы автоматически масштабируются и тарифицируются по использованию, а не по экземплярам машин.
Подобно тому как облачное хранилище заменило планирование мощностей (заблаговременное решение о том, сколько дисков покупать) моделью тарификации по использованию, бессерверный подход привносит тарификацию по использованию в выполнение кода: вы платите только за время фактического выполнения кода приложения, а не за заблаговременное выделение ресурсов.
Облачные вычисления против суперкомпьютинга
Облачные вычисления — не единственный способ построения крупномасштабных вычислительных систем; альтернативой служат высокопроизводительные вычисления (HPC), также известные как суперкомпьютинг. Несмотря на некоторые пересечения, HPC часто имеет иные приоритеты и использует другие методы по сравнению с облачными вычислениями и корпоративными системами дата-центров. Некоторые различия:
-
Суперкомпьютеры обычно используются для вычислительно интенсивных научных задач: прогнозирования погоды, климатического моделирования, молекулярной динамики (симуляция движения атомов и молекул), сложных задач оптимизации и решения дифференциальных уравнений в частных производных. Облачные вычисления применяются для онлайн-сервисов, корпоративных систем данных и подобных систем, которые должны обслуживать пользовательские запросы с высокой доступностью.
-
Суперкомпьютер обычно выполняет большие пакетные задания, которые периодически сохраняют состояние вычислений на диск. При сбое узла распространённое решение — остановить всю нагрузку кластера, отремонтировать неисправный узел и перезапустить вычисления с последней контрольной точки [55, 56]. В облачных сервисах остановка всего кластера обычно нежелательна, поскольку сервисы должны непрерывно обслуживать пользователей с минимальными перерывами.
-
Узлы суперкомпьютера обычно взаимодействуют через разделяемую память и прямой доступ к удалённой памяти (RDMA), что обеспечивает высокую пропускную способность и низкие задержки, но предполагает высокий уровень доверия между пользователями системы [57]. В облачных вычислениях сеть и машины часто используются взаимно не доверяющими организациями, что требует более надёжных механизмов безопасности — изоляции ресурсов (например, виртуальные машины), шифрования и аутентификации.
-
Сети облачных дата-центров часто основаны на IP и Ethernet, организованы в топологии Clos для обеспечения высокой пропускной способности сечения — общепринятой меры общей производительности сети [55, 58]. Суперкомпьютеры часто используют специализированные сетевые топологии — многомерные сетки и торы [59], которые дают лучшую производительность для HPC-нагрузок с известными паттернами коммуникации.
-
Облачные вычисления позволяют распределять узлы между несколькими географическими регионами, тогда как суперкомпьютеры обычно предполагают близкое расположение всех узлов.
Крупномасштабные аналитические системы иногда разделяют характеристики с суперкомпьютингом, поэтому знание этих методов может быть полезным при работе в данной области. Однако эта книга в основном посвящена сервисам, которые должны быть постоянно доступны, что рассматривается в разделе «Надёжность и отказоустойчивость».
Системы данных, право и общество
До этого момента в главе вы видели, что архитектура систем данных определяется не только техническими целями и требованиями, но также потребностями организаций, которые эти системы обслуживают. Инженеры систем данных всё чаще понимают, что удовлетворения потребностей собственного бизнеса недостаточно — мы также несём ответственность перед обществом в целом.
Особую озабоченность вызывают системы, которые хранят данные о людях и их поведении. С 2018 года Общий регламент по защите данных (GDPR) предоставил жителям многих европейских стран больший контроль и правовые гарантии в отношении их персональных данных, а аналогичное регулирование конфиденциальности было принято в различных других странах и штатах по всему миру, включая, например, Калифорнийский закон о конфиденциальности потребителей (CCPA). Регулирование в сфере ИИ, такое как Закон ЕС об искусственном интеллекте, накладывает дополнительные ограничения на использование персональных данных.
Более того, даже в областях, не подпадающих непосредственно под регулирование, растёт понимание воздействия, которое компьютерные системы оказывают на людей и общество. Социальные сети изменили то, как люди потребляют новости, что влияет на их политические взгляды и, следовательно, может повлиять на результаты выборов. Автоматизированные системы всё чаще принимают решения с серьёзными последствиями для отдельных лиц: кому предоставить кредит или страховое покрытие, кого пригласить на собеседование или кого подозревать в преступлении [60].
Все, кто работает с такими системами, разделяют ответственность за рассмотрение этических последствий и обеспечение соответствия применимому законодательству. Необязательно всем становиться экспертами в области права и этики, но базовое понимание правовых и этических принципов так же важно, как, скажем, основополагающие знания в области распределённых систем.
Правовые соображения влияют на сами основы проектирования систем данных [61]. Например, GDPR предоставляет людям право потребовать удаления своих данных по запросу (иногда называемое правом быть забытым). Однако, как мы увидим в этой книге, многие системы данных полагаются на неизменяемые конструкции, такие как журналы только для добавления, как часть своего дизайна — как обеспечить удаление данных из середины файла, который должен быть неизменяемым? Как обрабатывать удаление данных, которые были включены в производные наборы данных (см. «Системы записи и производные данные»), например в обучающие данные для моделей машинного обучения? Ответы на эти вопросы создают новые инженерные вызовы.
В настоящее время у нас нет чётких руководящих принципов о том, какие конкретные технологии или архитектуры систем следует считать «соответствующими GDPR». Регулирование намеренно не предписывает конкретные технологии, поскольку они могут быстро изменяться по мере развития технологий. Вместо этого правовые тексты устанавливают высокоуровневые принципы, подлежащие интерпретации. Это означает, что не существует простых ответов на вопрос о том, как соблюдать требования к конфиденциальности, но мы рассмотрим некоторые технологии в этой книге через эту призму.
В целом мы храним данные, потому что считаем, что их ценность превышает затраты на хранение. Однако стоит помнить, что стоимость хранения — это не только счёт за Amazon S3 или другой сервис: расчёт затрат и выгод должен также учитывать риски ответственности и ущерба репутации в случае утечки или компрометации данных злоумышленниками, а также риск правовых издержек и штрафов, если хранение и обработка данных будут признаны несоответствующими закону [51].
Правительства или правоохранительные органы также могут принуждать компании передавать данные. Когда существует риск, что данные могут раскрыть криминализированное поведение (например, гомосексуальность в нескольких странах Ближнего Востока и Африки или обращение за абортом в нескольких штатах США), хранение таких данных создаёт реальные угрозы безопасности для пользователей. Поездка в клинику для абортов, например, легко может быть выявлена по данным геолокации или даже по журналу IP-адресов пользователя (которые указывают приблизительное местоположение).
Учитывая все риски, может быть разумным решить, что некоторые данные просто не стоят хранения и поэтому должны быть удалены. Этот принцип минимизации данных (иногда известный под немецким термином Datensparsamkeit) противоречит философии «больших данных», предполагающей спекулятивное хранение большого количества данных на случай, если они окажутся полезными в будущем [62]. Но он соответствует GDPR, который предписывает, что персональные данные могут собираться только для конкретной, явно указанной цели, что эти данные не могут впоследствии использоваться для других целей и что данные не должны храниться дольше, чем необходимо для целей, для которых они были собраны [63].
Предприятия также обратили внимание на вопросы конфиденциальности и безопасности. Компании, выпускающие кредитные карты, требуют от предприятий, занимающихся обработкой платежей, строгого соблюдения отраслевых стандартов платёжных карт (PCI). Обработчики проходят регулярные проверки независимыми аудиторами для подтверждения постоянного соответствия требованиям. Поставщики программного обеспечения также столкнулись с усиленным контролем. Многие покупатели теперь требуют от поставщиков соблюдения стандартов Service Organization Control (SOC) Type 2. Как и в случае с соответствием PCI, поставщики проходят аудит третьих сторон для проверки соблюдения требований.
В целом важно балансировать потребности бизнеса с нуждами людей, чьи данные собираются и обрабатываются. Эта тема гораздо шире; в разделе [Ссылка будет добавлена] мы глубже рассмотрим вопросы этики и соответствия законодательству, включая проблемы предвзятости и дискриминации.
Заключение
Основной темой этой главы было понимание компромиссов — признание того, что для многих вопросов не существует единственно правильного ответа, а есть несколько различных подходов, каждый из которых имеет свои плюсы и минусы. Мы рассмотрели некоторые наиболее важные решения, влияющие на архитектуру систем данных, и ввели терминологию, которая понадобится в остальной части книги.
Мы начали с разделения операционных (транзакционных, OLTP) и аналитических (OLAP) систем и увидели их различные характеристики: они не только управляют разными типами данных с разными паттернами доступа, но и обслуживают разные аудитории. Мы познакомились с концепциями хранилища данных и озера данных, которые получают потоки данных из операционных систем через ETL. В главе 4 мы увидим, что операционные и аналитические системы часто используют совершенно разные внутренние структуры данных из-за различных типов запросов, которые им нужно обслуживать.
Затем мы сравнили облачные сервисы — сравнительно недавнее явление — с традиционной парадигмой самостоятельно размещаемого программного обеспечения, которая ранее доминировала в архитектуре систем данных. Экономическая эффективность каждого из этих подходов сильно зависит от конкретной ситуации, но неоспоримо, что облачно-ориентированные подходы вносят серьёзные изменения в архитектуру систем данных — например, в способе разделения хранилища и вычислений.
Облачные системы по своей природе распределённые, и мы кратко рассмотрели компромиссы распределённых систем по сравнению с использованием одной машины. Существуют ситуации, когда распределения избежать нельзя, но не стоит торопиться делать систему распределённой, если возможно оставить её на одной машине. В главе 9 мы подробнее рассмотрим проблемы распределённых систем.
Наконец, мы увидели, что архитектура систем данных определяется не только потребностями бизнеса, развёртывающего систему, но и регулированием конфиденциальности, которое защищает права людей, чьи данные обрабатываются — аспект, который многие инженеры склонны игнорировать. Как преобразовать правовые требования в техническую реализацию, пока не вполне понятно, но важно держать этот вопрос в уме при изучении остальной части книги.